Machine Learning for Artificial Intelligence (CIS 479)
Self-improvement of machine performance
Negative features of human learning
- slow
- inefficient
- expensive
- no copy process
- no-visible inspectable internal representation
- learning strategy is a function of knowledge
Learning Strategy
- rote learning
- learning by instruction
- learning by deduction {general rule}
- learning by analogy
- learning by induction {specification ® rule}
Two general approaches
- Numerical {fiddle with coefficients}
- Structural approaches {explore links}
Samuel’s Checkers Player
- mini-max alpha /beta pruning – three ply
- quiescent heuristic
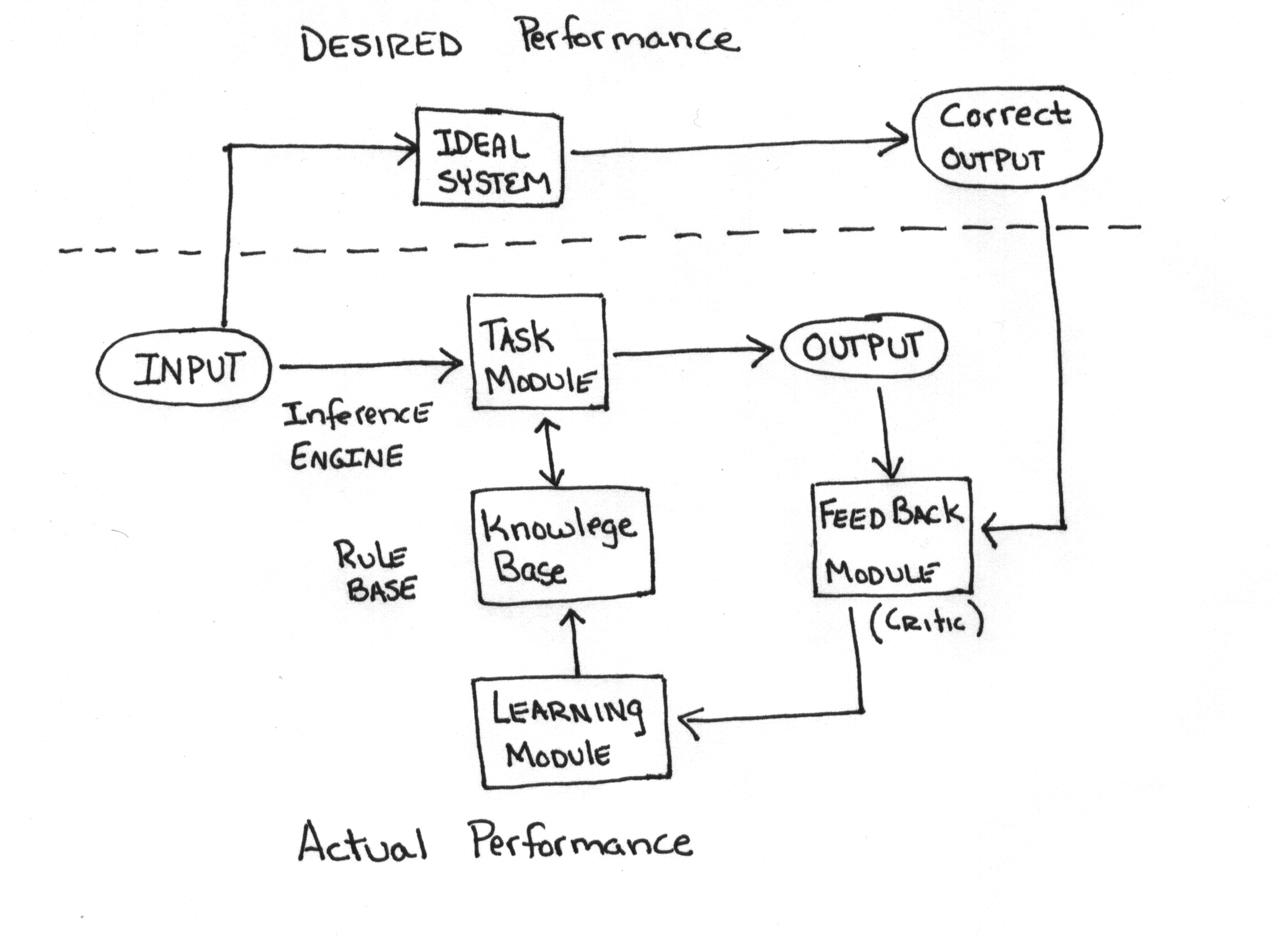
Learning Module
- Role learning- move for specific word configuration
- Search depth doubled
- Optimal direction when several alternatives exist
- Allows means of forgetting
- Learning Generalization
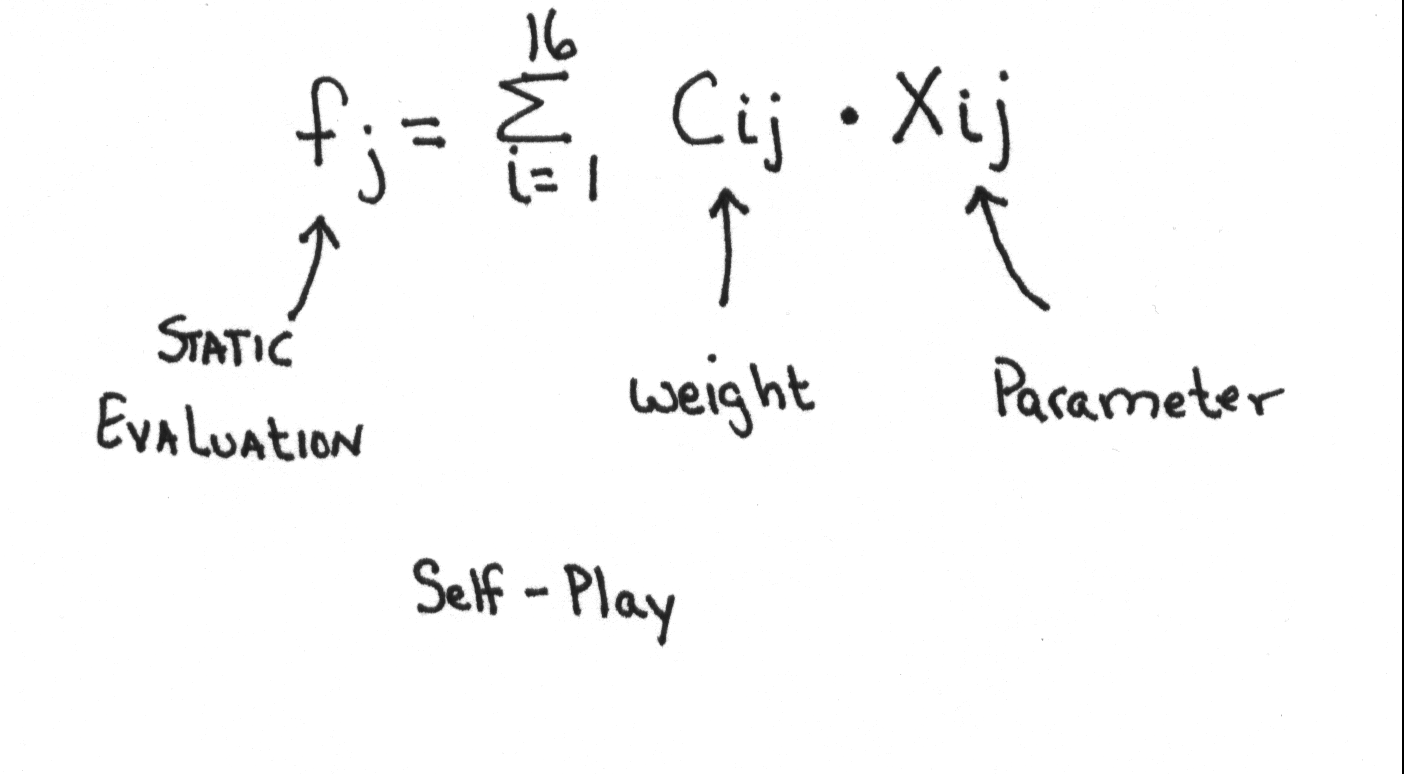
- Signature Table
Quilan –ID3
Classification of rules
- induced from example & non-examples
- Pioget Equilibrium
Lenat AM/Euriska
- AM – Automated mathematician
- Euriska- Learning by discovery
AM
- Select a concept to evaluate and then generate examples of it.
- Check examples for regularity if found then update the interestingness factor for that concept.
- Update interestingness
- Create new concept
- Create new connectives
- Propagates knowledge gains to other concepts in system
Induction Heuristics
Want agent procedure to use concept of square
- give "prototype" square
- allow system to devise initial description building semantic network
- require-link(model has link and near miss does not)
- forbid-link(near miss has link and model does not)
- climb-tree(isa inheritance- look for common ancestor)
- Enlarge-set(create a new class)
- Drop-link(incorrect model link)
- close (pick numeric value)
Specialize [make model more specific]
- match evolving model to example and match corresponding parts
- determine existence of single important difference between model and near miss
- if model has link and near miss does not then require link
- if near miss has link not in model then forbid link
- otherwise ignore example
Generalize [match more permissive]
- Match evolving model to get corresponding parts
- For each difference determine types
- if link points to class in model differences from class link in example
- then if classes are part classification tree then use climb tree
- if classes are from exhaustion set then drop-link
- otherwise use enlarged set
- if link is missing in example then drop-link
- if difference is number outside range then use close interval
- otherwise ignore difference
Learning Procedure [induce]
- let description of first example be initial description (cannot be non-example)
- For subsequent examples
- if example is near-miss then specialize
- if example is example then generalize
Felicity Conditions
- don’t learn something when in doubt
- wait and see
- no-altering principle
- learning in small steps
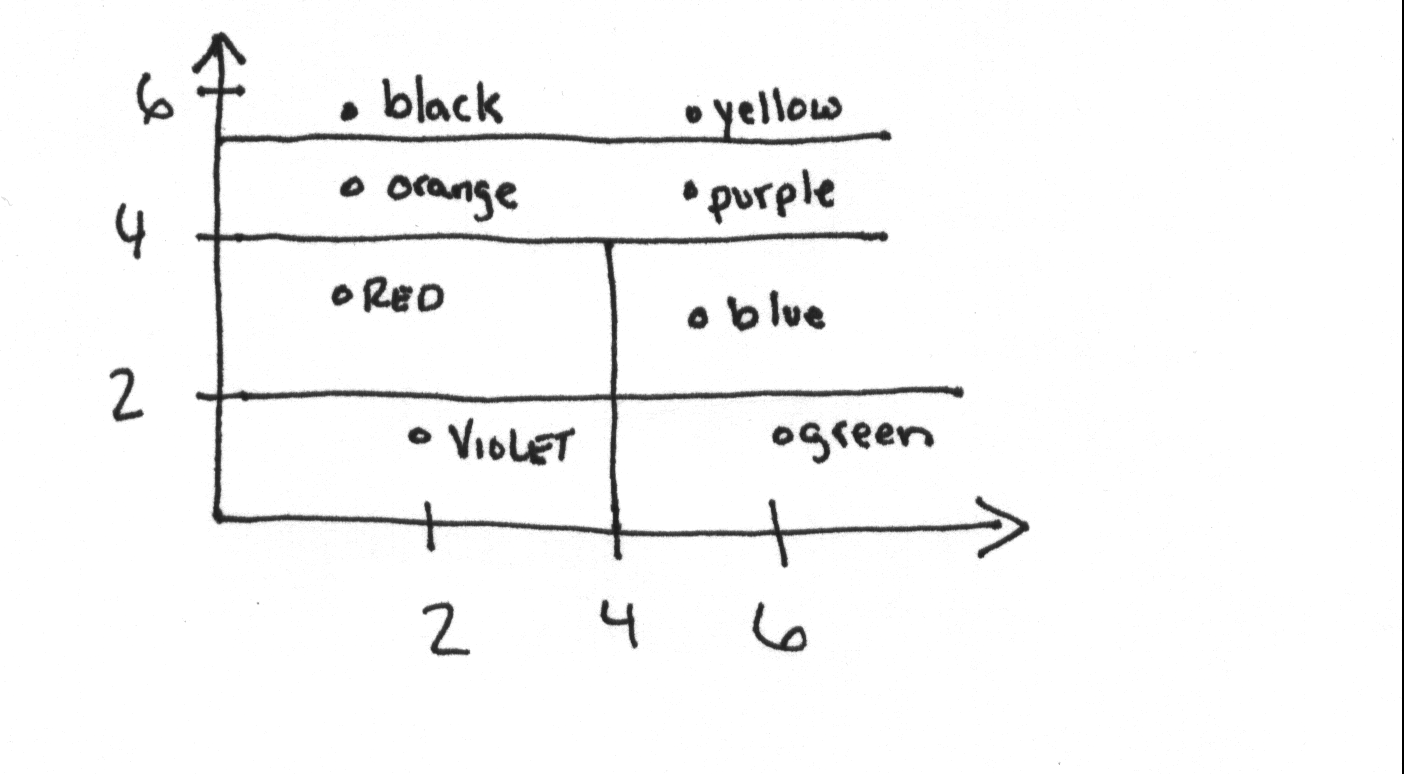
Learning by recording cases
- record cases do nothing until information is required
- Consistency heuristic (attribute feature of previously observed object)
- k-d tree (k-dimensional tree), nearest neighbor in feature space
k-d tree is decision tree
it is a semantic tree in which
- Each node is connected to a set of possible answers
- Each-node leaf is connected to a test that splits it set of possible answers into subsets
- Each branch carries a particular tree which results in subset of another node.
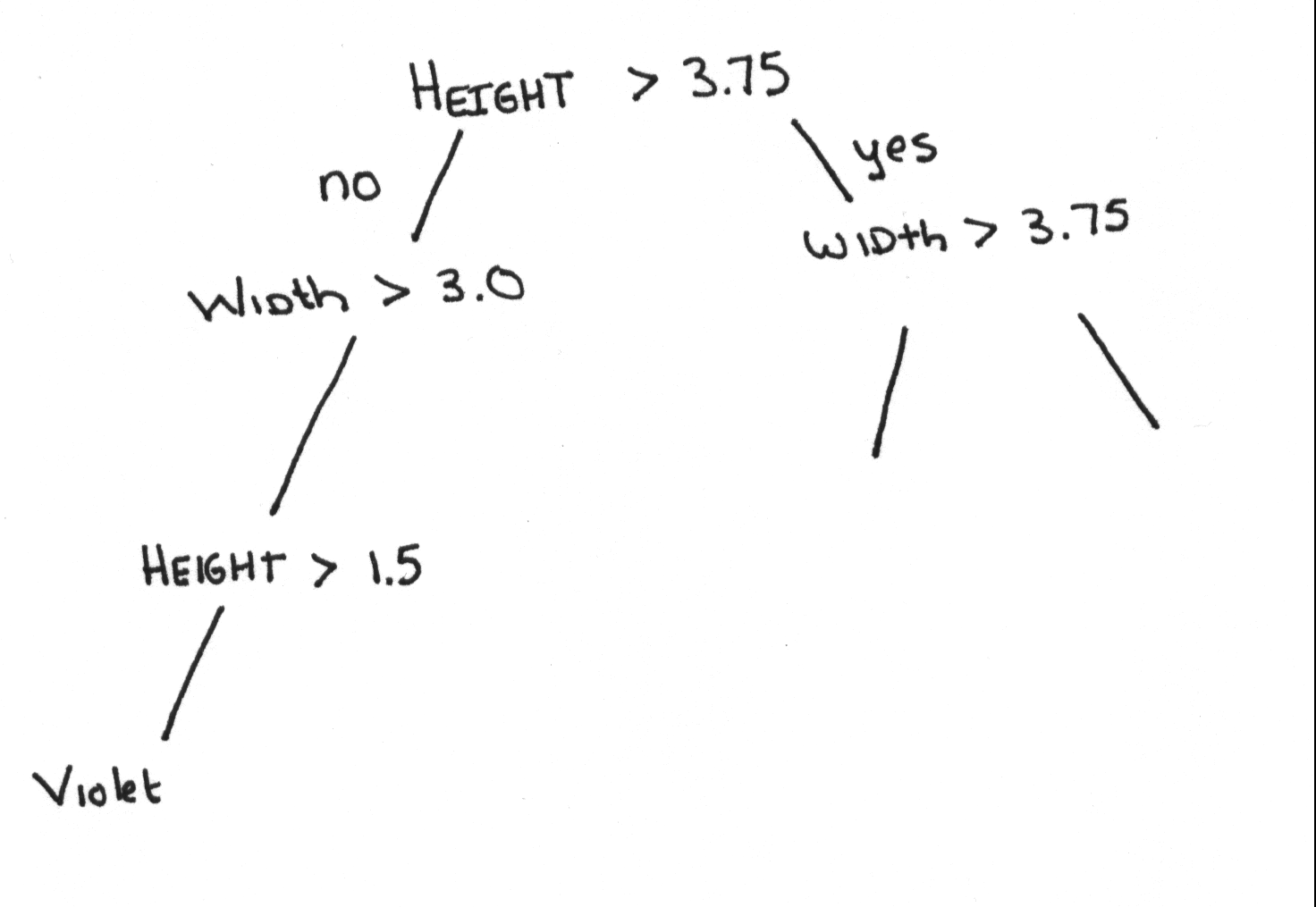
Building decision Tree
to divide cases into set
- if only one case then stop
- if first division then divide vertically use vertical dimension for comparison else
pick axis different from next higher level
- Constructing only the axes of comparison
- Find the average position of two middle objects
- Construct average threshold
- Construct decision tree test that compares unknown axes items against threshold
- note positions of middle objects in axis comparison
- call these values upper and lower bounds
- divide set objectives based on threshold, relative their position
- divide object in each subset